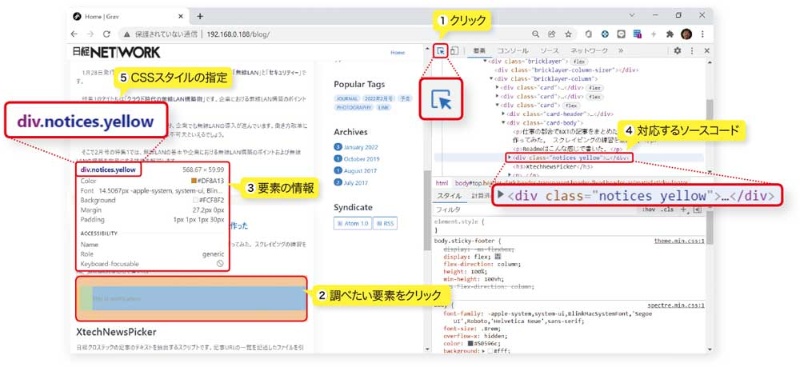
サイトからHTMLを抽出するにはどうすればいいですか?
インターネット上には、特定のサイトからHTMLを抽出して利用したい場合があります。そのための方法をいくつか紹介します。
Google Chrome でページのソースを取得する方法
Google Chromeを使えば、簡単にページのHTMLソースを取得することができます。次の手順に従ってください:
- 表示している画面の空白の箇所で右クリックします。
- 「ページのソースを表示」をクリックします。
- ソースが表示された画面上で右クリックします。
- 「名前を付けて保存」をクリックします。
- 「ファイルの種類」のドロップダウンリストから「ウェブページ、HTML のみ」を選択します。
- 「保存」をクリックします。
Webスクレイピングサービスやツールの利用
Webスクレイピングサービスやツールを使用することも有効な手段です。これらのサービスは、Visio、Octoparse、ParseHubなどがあります。
Webスクレイピングとは、Webサイトを巡回して指定した情報を取得し、その情報を加工して新しいデータを生成するためのプログラムです。以下に、人気のあるツールを表でまとめます。
| サービス名 | 特徴 |
|---|---|
| Octoparse | コード不要、クリック操作でスクレイピング可能 |
| ParseHub | シンプルなビジュアルインターフェース |
PythonでWebスクレイピングを行う
プログラミング経験のある方はPythonを使って自力でWebスクレイピングを行うこともできます。Pythonには、BeautifulSoupやRequestsといった強力なライブラリがあります。
以下に、PythonでHTMLを抽出する基本的なコード例を示します:
<!-- Pythonコード -->
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
print(soup.prettify()) </code>このコードは、指定されたURLからHTMLを取得し、きれいに整形されたHTMLを出力します。
Webスクレイピングを自力で実行するには、相応のプログラミング言語の学習が必要になります。プログラミング初心者や非エンジニア、ビジネス活用を急ぎたい方などにとって、自力でのWebスクレイピングは不向きです。専門のツールやサービスを利用することをお勧めします。
その他の参考記事: